Pfizer has been accused by the UK’s pharmaceutical watchdog of “bringing discredit” on the industry after senior executives used social media to promote an “unlicensed” Covid vaccine.
The company has been found to have breached the regulatory code five times, which also includes making misleading claims, failing to maintain high standards and promoting unlicensed medicines.
A ruling by the pharmaceutical watchdog, the Prescription Medicines Code of Practice Authority (PMCPA), relates to a complaint about a message posted on X, formerly known as Twitter, in November 2020 by senior Pfizer employees.
The complaint raised concern about Pfizer’s “misuse of social media to misleadingly and illegally promote their Covid vaccine”, according to the ruling.
They claimed that such “misbehaviour” on social media was “even more widespread” than they had thought and “extended right to the top of their UK operation”.
‘Unlicensed medicine proactively disseminated’
The complaint centered on a social media post on X by Dr Berkeley Phillips, the medical director of Pfizer UK. He shared a post from an employee of Pfizer in the US which said: “Our vaccine candidate is 95 per cent effective in preventing Covid-19, and 94 per cent effective in people over 65 years old. We will file all of our data with health authorities within days. Thank you to every volunteer in our trial, and to all who are tirelessly fighting this pandemic.”
Four other Pfizer employees, including one “senior” colleague, published the same message
The PMCPA ruling noted that this message contained “limited” information about the vaccine’s efficacy, no safety information and no reference to adverse events.
It went on to say that the social media post resulted in an “unlicensed medicine being proactively disseminated on Twitter to health professions and members of the public in the UK”.
A Pfizer UK spokesman said that the company “fully recognises and accepts the issues highlighted by this PMCPA ruling”, adding that it is “deeply sorry”.
They said: “Pfizer UK has a comprehensive policy on personal use of social media in relation to Pfizer’s business which prohibits colleagues from interacting with any social media related to Pfizer’s medicines and vaccines – backed by staff briefings and training.
“The personal use of social media by UK pharmaceutical industry employees in relation to company business is a challenging area for pharmaceutical companies, in which we continue to take all of the appropriate steps that are reasonably expected of a pharmaceutical company.”
As part of their response to the ruling, Pfizer said it had launched a review into its employees’ use of social media platforms to ensure compliance with their own rules as well as the regulatory code.
‘Accidental and unintentional’
It is the sixth time Pfizer has been reprimanded by the regulator over its promotion of the Covid-19 vaccine.
Following a complaint from the campaign group UsForThem, the PMCPA found that Pfizer had misled the public, made unsubstantiated claims and failed to present information in a balanced way.
Three of the other Pfizer cases related to LinkedIn posts, one related one was about claims made in a press release and one was about posts on X.
For the most recent series of breaches, Pfizer was charged administrative costs of £34,800.
Ben Kingsley, the head of legal affairs at UsForThem, said: “It’s astonishing how many times Pfizer’s senior executives have been found guilty of serious regulatory offences – in this case including the most serious offence of all under the UK Code of Practice. “Yet the consequences for Pfizer and the individuals concerned continue to be derisory. This hopeless system of regulation for a multi-billion dollar life and death industry has become a sham, in dire need of reform.”
Dr Phillips, the UK country medical director for Pfizer, said the social media post was “accidental and unintentional” adding: “That said, we immediately accepted the case ruling and do everything we can to ensure that our employees adhere to our strict social media policy and the industry Code of Practice when using their personal social media.”
David Watson of the Association of the British Pharmaceutical Industry (ABPI) said that the code of practice, which is overseen by the PMCPA, sets “high standards for companies that reflect and go beyond UK law”.
He added that cases that are found to have brought discredit on the industry are advertised in the medical, pharmaceutical, and nursing press.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
This was originally published by Glenn Greenwald on The Intercept, in 2014, then soon deleted from their website. But not from Internet. Tim Truth dug it out and I’m bring you the full set of receipts.
One of the many pressing stories that remains to be told from the Snowden archive is how western intelligence agencies are attempting to manipulate and control online discourse with extreme tactics of deception and reputation-destruction. It’s time to tell a chunk of that story, complete with the relevant documents.
Over the last several weeks, I worked with NBC News to publish a series of articles about “dirty trick” tactics used by GCHQ’s previously secret unit, JTRIG (Joint Threat Research Intelligence Group). These were based on fourclassifiedGCHQdocuments presented to the NSA and the other three partners in the English-speaking “Five Eyes” alliance. Today, we at the Intercept are publishing another new JTRIG document, in full, entitled “The Art of Deception: Training for Online Covert Operations.”
By publishing these stories one by one, our NBC reporting highlighted some of the key, discrete revelations: the monitoring of YouTube and Blogger, the targeting of Anonymous with the very same DDoS attacks they accuse “hacktivists” of using, the use of “honey traps” (luring people into compromising situations using sex) and destructive viruses. But, here, I want to focus and elaborate on the overarching point revealed by all of these documents: namely, that these agencies are attempting to control, infiltrate, manipulate, and warp online discourse, and in doing so, are compromising the integrity of the internet itself.
Among the core self-identified purposes of JTRIG are two tactics: (1) to inject all sorts of false material onto the internet in order to destroy the reputation of its targets; and (2) to use social sciences and other techniques to manipulate online discourse and activism to generate outcomes it considers desirable. To see how extremist these programs are, just consider the tactics they boast of using to achieve those ends: “false flag operations” (posting material to the internet and falsely attributing it to someone else), fake victim blog posts (pretending to be a victim of the individual whose reputation they want to destroy), and posting “negative information” on various forums. Here is one illustrative list of tactics from the latest GCHQ document we’re publishing today:
Other tactics aimed at individuals are listed here, under the revealing title “discredit a target”:
Then there are the tactics used to destroy companies the agency targets:
GCHQ describes the purpose of JTRIG in starkly clear terms: “using online techniques to make something happen in the real or cyber world,” including “information ops (influence or disruption).”
Critically, the “targets” for this deceit and reputation-destruction extend far beyond the customary roster of normal spycraft: hostile nations and their leaders, military agencies, and intelligence services. In fact, the discussion of many of these techniques occurs in the context of using them in lieu of “traditional law enforcement” against people suspected (but not charged or convicted) of ordinary crimes or, more broadly still, “hacktivism”, meaning those who use online protest activity for political ends.
The title page of one of these documents reflects the agency’s own awareness that it is “pushing the boundaries” by using “cyber offensive” techniques against people who have nothing to do with terrorism or national security threats, and indeed, centrally involves law enforcement agents who investigate ordinary crimes:
No matter your views on Anonymous, “hacktivists” or garden-variety criminals, it is not difficult to see how dangerous it is to have secret government agencies being able to target any individuals they want – who have never been charged with, let alone convicted of, any crimes – with these sorts of online, deception-based tactics of reputation destruction and disruption. There is a strong argument to make, as Jay Leiderman demonstrated in the Guardian in the context of the Paypal 14 hacktivist persecution, that the “denial of service” tactics used by hacktivists result in (at most) trivial damage (far less than the cyber-warfare tactics favored by the US and UK) and are far more akin to the type of political protest protected by the First Amendment.
The broader point is that, far beyond hacktivists, these surveillance agencies have vested themselves with the power to deliberately ruin people’s reputations and disrupt their online political activity even though they’ve been charged with no crimes, and even though their actions have no conceivable connection to terrorism or even national security threats. As Anonymous expert Gabriella Coleman of McGill University told me, “targeting Anonymous and hacktivists amounts to targeting citizens for expressing their political beliefs, resulting in the stifling of legitimate dissent.” Pointing to this study she published, Professor Coleman vehemently contested the assertion that “there is anything terrorist/violent in their actions.”
Government plans to monitor and influence internet communications, and covertly infiltrate online communities in order to sow dissension and disseminate false information, have long been the source of speculation. Harvard Law Professor Cass Sunstein, a close Obama adviser and the White House’s former head of the Office of Information and Regulatory Affairs, wrote a controversial paper in 2008 proposing that the US government employ teams of covert agents and pseudo-”independent” advocates to “cognitively infiltrate” online groups and websites, as well as other activist groups.
Sunstein also proposed sending covert agents into “chat rooms, online social networks, or even real-space groups” which spread what he views as false and damaging “conspiracy theories” about the government. Ironically, the very same Sunstein was recently named by Obama to serve as a member of the NSA review panel created by the White House, one that – while disputing key NSA claims – proceeded to propose many cosmetic reforms to the agency’s powers (most of which were ignored by the President who appointed them).
But these GCHQ documents are the first to prove that a major western government is using some of the most controversial techniques to disseminate deception online and harm the reputations of targets. Under the tactics they use, the state is deliberately spreading lies on the internet about whichever individuals it targets, including the use of what GCHQ itself calls “false flag operations” and emails to people’s families and friends. Who would possibly trust a government to exercise these powers at all, let alone do so in secret, with virtually no oversight, and outside of any cognizable legal framework?
Then there is the use of psychology and other social sciences to not only understand, but shape and control, how online activism and discourse unfolds. Today’s newly published document touts the work of GCHQ’s “Human Science Operations Cell,” devoted to “online human intelligence” and “strategic influence and disruption”:
Under the title “Online Covert Action”, the document details a variety of means to engage in “influence and info ops” as well as “disruption and computer net attack,” while dissecting how human beings can be manipulated using “leaders,” “trust,” “obedience” and “compliance”:
The documents lay out theories of how humans interact with one another, particularly online, and then attempt to identify ways to influence the outcomes – or “game” it:
We submitted numerous questions to GCHQ, including: (1) Does GCHQ in fact engage in “false flag operations” where material is posted to the Internet and falsely attributed to someone else?; (2) Does GCHQ engage in efforts to influence or manipulate political discourse online?; and (3) Does GCHQ’s mandate include targeting common criminals (such as boiler room operators), or only foreign threats?
As usual, they ignored those questions and opted instead to send their vague and nonresponsive boilerplate: “It is a longstanding policy that we do not comment on intelligence matters. Furthermore, all of GCHQ’s work is carried out in accordance with a strict legal and policy framework which ensures that our activities are authorised, necessary and proportionate, and that there is rigorous oversight, including from the Secretary of State, the Interception and Intelligence Services Commissioners and the Parliamentary Intelligence and Security Committee. All our operational processes rigorously support this position.”
These agencies’ refusal to “comment on intelligence matters” – meaning: talk at all about anything and everything they do – is precisely why whistleblowing is so urgent, the journalism that supports it so clearly in the public interest, and the increasingly unhinged attacks by these agencies so easy to understand. Claims that government agencies are infiltrating online communities and engaging in “false flag operations” to discredit targets are often dismissed as conspiracy theories, but these documents leave no doubt they are doing precisely that.
Whatever else is true, no government should be able to engage in these tactics: what justification is there for having government agencies target people – who have been charged with no crime – for reputation-destruction, infiltrate online political communities, and develop techniques for manipulating online discourse? But to allow those actions with no public knowledge or accountability is particularly unjustifiable.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
There’s really not much to comment, this just needs everyone’s urgent attention and a huge backlash!
Enter (not!) UK’s top retailer:
This guy makes a pretty good summary here, but I recommend going into all details yourselves, because there are plenty more clues about what they plan for us.
All I need to add before you get into the document: No less than the plebs they despise, even more acutely, I’d say, these guys don’t seem to differentiate very well between their wishes and the actual reality occurring outside their brains. Many of the things presented as facts or real data points are no more real than their 2169 predictions. I think experts call that “schizophrenia” and, by my observations, it’s the most widespread and long lasting pandemic on the planet. Also, note how they admit to creating a feedback loop by controlling both food and drugs. This is what Monsanto, Bill Gates and Bayer have long created.
Governments around the world are cracking down on food production in ways that will make it HARDER to grow and purchase food. Amish farmers are even going to jail for refusing to fall in line. But US Rep. Thomas Massie (R-KY) has a solution: a simple amendment to the Constitution that will add the “right to grow food and purchase food from the sources that you want.” Rep. Massie joins Glenn to explain what the amendment would do and how he has worded it to ensure that the government won’t abuse it to create a larger welfare state. This has nothing to do with food stamps, he argues. It’s about restricting the government’s ability to tell YOU what you should grow and buy.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
Q: What’s the difference between “non-elites” and “useless eaters”? A: Three years.
As unfathomable as it may seem to educated people (which is a different thing from “schooled people”), I still encounter many NPCs retaining antiquated knee-jerk rejection reactions to the concept of a definite and established ruling elite class hoovering over the plebs in a superior societal level. Most of these NPCs are unfixable, but for the remaining few…
The word “elite” appears eight times in seven pages.
In an effort to hear more views departing from elite consensus, the Commission will support and welcome a new set of fellows who will articulate and represent views from rural and other areas to help ensure this diversity becomes engrained in our deliberations.
The Trilateral Commission, 2019
And there’s a “gap” between their highnesses and “the rest of the citizens”…
Domestic Dialogues. Strengthening our democracies requires building more “connective tissue” between traditional elites and other members of our own societies. Trilateral Commission domestic dialogues will bring together “coastal elites” and individuals from rural and other areas. The two-day dialogues, taking place in different locations in the heart of the North American continent, will each be organized around a concrete issue—such as urban renewal, manufacturing, or various aspects of the energy industry. This structure will allow participants to learn and to interact while giving them an opportunity to informally discuss what is straining our democracies, without the perception of one side lecturing to the other. The dialogues may focus on the younger generation of Commission members (the under-35 David Rockefeller Fellows) or be a hybrid of full members and fellows.
The Trilateral Commission, 2019
Bonus:
If you ever wondered why democracy is under inside attack from the democratically elected governments, the answer is old and simple, as this next document proves:
Democracies are becoming ungovernable with time as they foster an accumulation and consolidation of power for the general population at the expense of government.
Of course democracy is just another logically absurd utopia, but if we were to adopt that framework, these two sentences above are the root cause of everything, forcing the governments to push us down regularly, to re-establish dominance and control.
The corollary is that governments do only one thing: they self-consolidate at the expense of the people they are hired to serve. As Chomsky has long demonstrated, the government and their people have always been at odds, not symbiots. Same way government is at odds with democracy itself.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
The world of technology is changing rapidly, and with it comes the development of new communication protocols like the Internet of Behavior (IoB). IoB offers a revolutionary way to monitor, control and model human behavior. As tech leaders in this ever-evolving industry, we must stay ahead of upcoming trends so that we can take advantage of its many benefits.
The Internet of Behavior
IoB is a system that uses sensors and other technologies to monitor, analyze and predict human behavior. It combines artificial intelligence (AI), machine learning (ML), big data analytics, cloud computing, Internet of Things (IoT) devices, mobile applications, wearable devices, augmented reality (AR), virtual reality (VR), robotics automation systems and more into one comprehensive platform for collecting behavioral data from individuals or groups. The collected data can then be used for various purposes such as predictive analytics or automated decision-making processes.
The primary benefit of using IoB technology is improved efficiency and productivity gains from automation enabled by predictive analytics. Leveraging AI algorithms for analyzing behavioral patterns in real time can help organizations make better decisions faster while reducing costs associated with manual labor or inefficient processes.
The Internet of Behavior is a rapidly growing technology that has the potential to revolutionize how we interact with and understand our world. In this article, I will explore how IoB works and what technologies are used to implement it.
How IoB Works
IoB is a revolutionary technology that enables the monitoring, control and modeling of human behavior. It combines the power of the technologies mentioned above to provide an unprecedented level of insight into how people interact with their environment. IoB has been used in various industries such as healthcare, retail, finance, education, transportation and more.
Protocols And Ecosystems Involved In IoB
IoB works by connecting devices to each other through networks or protocols like Bluetooth Low Energy (BLE). This connection allows for real-time data exchange between different systems, which can then be analyzed using AI algorithms. Additionally, these connections are often secured using encryption techniques like Transport Layer Security (TLS) to ensure privacy protection. Furthermore, this ecosystem also includes software platforms such as Amazon Web Services or Microsoft Azure which enable organizations to store large amounts of data securely in the cloud while providing scalability options when needed.
Technologies Used To Implement IoB
In order for IoB systems to work effectively, they must utilize several technologies, including sensors that detect changes in environmental conditions, communication protocols such as Wi-Fi or BLE, edge computing capabilities that allow for local processing, ML algorithms that analyze collected data, databases for storing information and APIs that facilitate integration with other applications or services. All these components come together to create an intelligent system capable of understanding user behavior patterns over time so it can make predictions about future actions based on past behaviors.
Challenges Of Developing And Implementing IoB
It is important to understand the protocols and ecosystems involved in IoB, as well as the technologies used to implement it, so you can unlock the potential of this powerful technology for improved efficiency, security and accuracy. Let’s explore further how these advantages can be leveraged with IoB for human behavior monitoring, control and modeling.
Advantages Of Using IoB For Human Behavior Monitoring, Control And Modeling
Automation and predictive analytics enabled by IoB can significantly improve efficiency and productivity gains. For example, IoB systems can be used to automate mundane tasks such as data entry or scheduling appointments, freeing up time for more complex activities that require higher-level thinking skills. Additionally, predictive analytics enabled by IoB can help identify patterns in customer behaviors that may not be immediately apparent to the naked eye.
Enhanced security and privacy protection are other advantages of using IoB for human behavior monitoring, control and modeling. Advanced data encryption techniques are used in these systems, which ensure that sensitive information remains secure at all times while still allowing access only when necessary.
The advantages of using IoB in this way have been demonstrated in terms of improved efficiency and security as well as increased accuracy. As the technology continues to evolve, we will see more sophisticated AI-based solutions emerging and greater emphasis on interoperability standards.
Upcoming Trends In The Development And Use Of IoB Technology
The development and use of IoB technology are rapidly evolving, with new trends emerging in the industry. AI-based solutions are becoming increasingly popular for automated behavioral analysis enabled by this technology. These solutions can help to identify patterns in user behavior that would otherwise be difficult to detect manually. This could include identifying potential security threats or uncovering customer preferences and insights from large datasets. Wearable devices are also gaining traction as an alternative to traditional sensors for collecting behavioral data. They offer a more convenient way of gathering information about user activities without having to install additional hardware or software components on the device itself.
Interoperability standards are also being developed with increasing focus, allowing different platforms utilizing IoB technology to integrate seamlessly across different systems and networks. This will enable users to access data collected from multiple sources within one platform, providing a comprehensive view of their behaviors over time while maintaining privacy and security protocols throughout the process.
Conclusion
In conclusion, the Internet of Behavior is a new communication protocol and ecosystem that promises to revolutionize the way we monitor, control and model human behavior. By leveraging the latest advances in technology such as artificial intelligence and machine learning algorithms, IoB can provide us with unprecedented insights into how people interact with each other and their environment. As this technology continues to evolve, it will become increasingly important for tech leaders to stay abreast of its development so they can leverage its potential benefits for their organizations. – End of Forbes article
Standard PR piece, ChatGPT redacted, I guess… But damn worrying escalation from the previous piece on the Internet of Bodies and Internet of Things, or about optogenetics! And we’re not talking about potential for abuse here because this is an abuse technology, abuse is what it does. With no one’s consent.
I didn’t even bother to check with google, but on any other search engine you get a lot of hits for “internet of behavior”, the secret is hidden in the open, as usual. but I leave you with a few of my own findings and resources, and from here there’s no way around knowing your enemy to escape and defeat your enemy.
The most obvious and effective examples of capitalizing on the Internet of Behaviours are Facebook and Google, which display adverts to surfers at frequent intervals depending on the detailed analysis and understanding they have created from consumer behavioral data obtained on a regular basis.
The global internet of behaviors (IoB) market size was valued at USD 402.6 billion in 2022 and is expected to surpass around USD 3592.6 billion by 2032, poised to grow at a compound annual growth rate (CAGR) of 24.97% from 2023 to 2032.
The Internet of Behaviours (IoB) seeks to debate how data may be best understood and is used to build and launch new products from the perspective of human psychology. The IoB may be utilized in a variety of ways by both public and commercial enterprises. This innovation will become an enticing big branding and distribution platform for businesses and organizations all around the world. Every firm gets an in awareness of its clientele, which the IoB platform enables. For instance, IoB links all mobile phones in the program, allowing them to observe their faults and receive visual tips on how to improve their swinging and stroke. The linking of devices generates a large number of new pieces of data and spans beyond the Internet of Things (IoT). Businesses acquire information from customers by ‘sharing’ data amongst linked devices, which are then monitored in real time by a single computer.
While refers to the interconnection of networked physical things that acquire and exchange data over the internet. IoB interprets this data in conjunction with particular human actions ranging from purchasing habits to demographic preferences. Location tracking, big data, and face recognition devices basically map client behavior. Here’s an easy example: Uber. Its Internet of Things app monitors both drivers with passengers. Once the consumer has been left off, Uber polls to assess the ride, allowing the driver’s conduct to be monitored and the quality of customer to be interpreted properly. By 2025, 40% of the world population would be subject to at least 1 IoB program (government or corporate) and digitally tracked in order to affect human behavior. IoB may be a great instrument for leveraging sales and marketing to develop effective strategies that make a difference in the products and services given to customers. But that’s not all; it’s also beneficial to other industries. IoB, for example, is useful in the medical arena, assisting healthcare personnel in assessing individuals’ illnesses, responsiveness to medicines, and other lifestyle information.
Growth factors
Over the last decade or so, there has been an astonishing increase in chronic and weakens the immune system illnesses (NCDs). Every year, over 41 million individuals die as a result of NCDs, resulting in exorbitant healthcare cost. IoB-enabled devices have enabled significant advancements in artificial pancreas technology. According to 2015 research, IoB devices resulted in a 50% reduction in 30-day hospital readmissions. IoB aids in the reduction of automobile insurance premiums. Users can install an app on their phones that collects crucial information such as distance traveled, automobile speed, and time of day the user is driving, and so on. As a result, determine the right premium that the user is entitled to pay. According to the study, prudent drivers would pay minimal rates. Aviva was the first insurance provider to create a smartphone app for tracking driving behavior in 2013.
Several digital advertising firms are already utilizing analytics technologies to gain insights into regular customer habits. Marketers may utilize the Internet of Things to monitor client purchasing behaviors across platforms, gain access to previously unavailable data, reconfigure the value chain, and even bring honest point-of-sale notifications and customized marketing. IoB is regarded as one of the top technology trends for 2021. The COVID-19 epidemic is mostly to blame for IoB becoming a trend since it has revolutionized how consumers engage with brands, forcing businesses to reconsider how they communicate with customers. From the angle of human psychology, the IoB concept attempts to accurately analyze data and use that understanding to build and market new things. The IoB attempts to understand data obtained from users’ online actions from the perspective of behavioral psychology. It seeks to address questions about how to analyze data and how to apply that information to develop and market new products, all from the standpoint of human psychology. This new approach occasionally has an impact on Quality Infrastructure since many organizations might increase their connectivity.
Using IoB technology has assisted numerous firms in reaching out to more clients through internet advertising. Companies may easily identify and target certain individuals or groups to offer their services and goods using the Internet of Behavior. Google and Facebook, for example, both utilize behavioral data to provide relevant adverts to its customers. Companies may use IoB to not only communicate with their target audience, but also track their habits in order to enhance services. Furthermore, new technologies such as Alexa, OK Google, and Siri are designed to study and analyze data and human behavior in order to perform more effectively.
Report Scope of the Internet of Behaviors (IoB) Market
Advertising Campaigns, Digital Marketing, Content Delivery, Brand Promotion, and Others are the market segments. Over the projected period, the Digital Marketing sector is likely to occupy a major proportion of the worldwide Internet of Behaviors (IoB) market. Because the internet of behavior (IoB) requires an internet connection, digital marketing services will benefit greatly from IoB technology. Data is the key commodity of digital marketing, which promotes products and services to consumers all over the world. If companies have access to behavioral analysis and interpretation technology, they will be better positioned to engage customers following the purchase process.
In 2022, the digital marketing category is expected to have the highest share. Because an internet connection is required for the internet of behavior (IoB), digital marketing services will benefit the most from IoB technology. Digital marketing is a field that markets products and services to individuals all over the world using data as its primary commodity. They will be in a better position to contact customers at the conclusion of the purchasing process if they have access to tools for behavioral analysis and interpretation. Globally, there is expected to be a major increase in digital marketing. Digital marketing will be used to promote brands, generate leads, and increase sales. The Internet of Business is a big boon to the sales profession. At the same time, for decades, corporations relied on data to make judgments. Why has the IoB trend become so important in today’s commercial, government, and non-profit sectors? First and foremost, IoB focuses on gathering, analyzing, and comprehending user behavior in order to enhance service quality and the value chain. This technology collaborates closely with behavioral science and can provide greater data insights. It also aids in the development of stronger client connections because IoB allows for two-way contact with them. Instead of doing surveys to learn from them, businesses may better understand their consumers’ demands and deliver significant improvements.
Industry Insights
BFSI, Telecom and IT, Media and Entertainment, Tourism & Travel, Retail and e-Commerce, Healthcare, Manufacturing, and Others are the major segments. The BFSI category is expected to occupy a considerable part of the worldwide Internet of Behaviors (IoB) market by 2032. IoB is extensively utilized in the BFSI business for statement generation and automatic notification applications. Brands may maintain an omnichannel presence by swiftly determining a customer’s preferred channels and providing tailored messaging solely through those channels. Consumer connection is being prioritized by financial institutions and retail banks through location-based advertising. These reasons are expected to drive IoB adoption in the BFSI industry.
The most obvious and effective examples of capitalizing on the Internet of Behaviours are Facebook and Google, which display adverts to surfers at frequent intervals depending on the detailed analysis and understanding they have created from consumer behavioral data obtained on a regular basis. However, collecting and analyzing data from IoT is difficult, and many businesses do not have simple access to this data. With the number of IoT devices predicted to triple by 2025, IoT, which has so far had momentum in the B2B industry, is expected to experience rapid acceptance in the consumer segment.
Regional Insights
The adoption of the internet of behaviors in North America is expected to rise at a rapid pace. Furthermore, North America has made significant progress in the use of IoT, particularly in the industrial and automotive industries. Because of the demand for IoT, cloud platforms are seeing widespread acceptance, boosting the growth of the internet of behaviors market throughout the forecast period.
South Asia and the Pacific are expected to emerge as the most opportunistic markets for the internet of behaviors due to the presence of a large consumer population, creating opportunities for organizations engaged in behavioral analytics to better understand consumer behavior and strategize their sales/marketing campaigns accordingly. Furthermore, rising government smart city efforts and cloud investment in the area are expected to fuel market expansion in the near future. Furthermore, the introduction of high-speed networking technologies, increased interest in the area by international firms, and rising demand from developing countries such as India, Indonesia, and Australia are expected to boost market expansion.
Key market developments
Aware, Inc., a major global provider of biometrics software products, solutions, and services, will exhibit its digital identification expertise in many sessions at the Identity Week London 2021 conference, which will be held from September 22 to 23 in London, England. Identity Week London is an ideal venue for Aware to showcase its extensive biometric expertise and solutions for password-less authentication and identity ownership, with a focus on digital identity and complex authentication technologies.
Maxar Technologies’ AFIXTM suite of biometric products was bought by Aware, Inc., a prominent global provider of biometrics software products, solutions, and services, in November 2020. The Aware ABIS product line has expanded with the inclusion of AFIX, which provide turn key also face and fingerprint biometrics matching, in addition forensic analysis softwares for small and medium-sized law enforcement and government organizations.
Internet of behaviour is an extension of IoT. Let us try to know more about it. It’s not about the “things” at all when companies use the Internet of Things to persuade us to change our habits. We’ve crossed over into the Internet of Behavior as the IoT connects individuals with their activities.
Consider the IoB as a mash-up of three disciplines:
Technology
Analytical data
Psychology is the study of human behaviour.
Emotions, choices, augmentations, and companionship are the four areas of behavioural science that we examine when we utilize technology.
Companies that know us through the data provided by IoT, can now influence our behaviour using the data provided by IoB. Consider using a smartphone health app to check your nutrition, sleep habits, heart rate, or blood sugar levels. The app can warn you about potentially dangerous circumstances and propose behaviour changes that would lead to a more positive or desirable outcome.
For the time being, corporations are mostly using IoT and IoB to watch and attempt to influence our behaviour to reach Allstate behavior their intended goal—typically, to purchase.
Working of IoB
How Data Is Collected?
Consumer data may be gathered from a range of sites and technologies, including a company’s website, social media profiles, sensors, telematics, beacons, health monitors (such as Fitbit), and a variety of other devices.
Each of these sites gathers various types of information. For example, a website may keep track of how many times a person visits a certain page or how long they remain on it. Furthermore, telematics may track how hard a vehicle’s driver brakes or the vehicle’s typical speed.
Data is collected and analyzed by businesses for a variety of purposes. These reasons include assisting businesses in making educated business decisions, customizing marketing techniques, developing products and services, and driving user experience design, among others.
Companies establish standards to aid in the analysis of this data. When a user performs a specific action(s), the firm then begins to convince the user to modify their behaviour. For instance, if a user visits a company’s page selling men’s slim jeans three times, the digital shop may show them a pop-up ad offering them 25% off a pair of jeans.
Using Data from a Variety of Sources
Combining data from many sources and evaluating it to make a decision is another component of the Internet of Behaviors. Companies may develop in-depth user profiles for each user by combining data from a variety of sources. These profiles may then be looked at to see what the best course of action is for the person.
For example, on the brand’s Instagram page, a customer called Ted comments on a photo of a new sneaker. Ted visits the brand’s website a few days later and looks at the identical sneaker. After a week, Ted is watching an ad for the sneaker on YouTube. In the meanwhile, the brand is keeping track of all of Ted’s digital content touchpoints.
Because Ted has expressed an interest in the brand’s shoe, the brand may synthesize this information and devise a strategy for converting Ted into a customer. Remarketing display advertising or emailing Ted a discount coupon are examples of actions the brand might do.
Use of IoB in Various Sectors
IoB in Business
Online advertising is increasingly being used by a variety of businesses to reach out to their clients. They may discover and target certain persons or groups that could benefit from their products or services with the help of IoB.
Both Google and Facebook utilize behavioural data to provide ads to users on their sites. This enables companies to interact with their target consumers and measure their behaviour in response to advertisements via “click rates.”
Similarly, Youtube uses behavioural analytics to enhance the viewer’s experience by only recommending or highlighting videos and subjects that they are interested in.
IoB During the Covid-19 Pandemic
The epidemic has increased our awareness of the precautions we must take during this period. Employers might use sensors or RFID tags to see if there are any inconsistencies in following safety standards. Restaurants and food delivery applications, for example, utilize the protocol information to guide their decisions.
Swiggy and Zomato, for example, both exhibited and promoted restaurant safety procedures. They also recorded and broadcast the temperature of the delivery person to reassure consumers that they were safe.
IoB for the Insurance Industry
In the insurance industry, IoB may be quite beneficial. Driver tracking tools are already used by insurance companies like Allstate and StateFarm to track and secure a driver’s conduct. With the help of IoB, they may evaluate the behaviour and perhaps determine if a certain occurrence was an accident or a misjudged assumption on the part of the insured.
This can help prevent incidents of drunk driving, driving under the influence of drugs, and even underage or retired persons from getting behind the wheel and causing an accident.
End-Note
The Internet of Behaviors offers businesses cutting-edge methods for marketing products and services as well as influencing user and employee behaviour. This technology is highly useful to organizations since it allows them to optimize their customer relationships depending on the data acquired.
Behavioral data technology is still developing. However, as new IoT devices proliferate, the argument over what constitutes critical data and ethical use is only beginning.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
! Articles can always be subject of later editing as a way of perfecting them
Israeli visit disclosed by Avigdor Lieberman, who says Mossad chief and Israeli military commander were sent on the mission by Netanyahu
Mossad Chief Yossi Cohen visited Doha on February 5 in order to ensure Qatar continues its financial aid policy to the Hamas-controlled Gaza Strip.
The visit came to light in an interview former Defense Minister Avigdor Lieberman gave Israel’s Channel 12 News on Saturday, saying Prime Minister Benjamin Netanyahu had sent Cohen and the Israeli military’s chief of Southern Command Herzl Halevi to “beg the Qataris to keep funneling money into Hamas.”
“Both the Egyptians and the Qataris are angry with Hamas, and they were going to cut all ties with them. All of a sudden Netanyahu shows up as a Hamas advocate, pressuring Egypt and the Qataris to continue” with the financial support, said Lieberman, adding that Netanyahu’s policy is tantamount to “surrender to terrorism.”
According to Walla news website, Cohen and Halevi stayed in Doha for less than 24 hours, meeting with the Qatari envoy to the Gaza Strip Mohammed al-Emadi and Qatari national security advisor Mohammed Bin Ahmed al-Misnad.
On Friday, Doha announced that it would increase Gaza Strip aid as part of the efforts to alleviate conditions and increase stability in the enclave. Qatar has transferred the Gaza Strip over $1 billion since 2012 with Israel’s approval, according to data presented by an international source to Israeli ministers in 2019.
As part of the improved aid package, some 120,000 impoverished families will receive $100 dollars each by the end of February.
Moreover, poor-stricken families will receive financial support to pay for the rehabilitation of their homes totaling a million dollars, and an additional million dollars in aid to 500 young Palestinians from those families who are about to get married. Another million dollars will be given to Gazan students whose families are unable to pay their tuition.
Al-Emadi added that $24 million will be allocated to building a new hospital in the Rafah area in southern Gaza.
In November 2019, Qatar began a six-month, $150 million program to fund civil servant wages and shipments of fuel for power generation in Gaza, offering a measure of reprieve to the blockaded enclave under the control of militant group Hamas. Qatar then gave $70 million dollars to 70 needy families.
More Israelis Speak Out – Hamas Attack Inside Job
A secret Mossad Qatar trip, Hamas outreach to Egypt and Iran’s threat
In Israel, the Mossad-Qatar-Hamas story was revealed by Yisrael Beytenu leader Avigdor Liberman over the weekend and was reported locally.
Hamas official Ismail Haniyeh (R) and the Emir of Qatar Sheikh Hamad bin Khalifa al-Thani arrive at a cornerstone laying ceremony in the southern Gaza Strip(photo credit: REUTERS)
Saudi news channel Al Arabiya is very interested in what a previously unknown “Mossad trip to Qatar” means for the region. “Egypt and Qatar are angry with Hamas, and they intended to cut ties with it,” the network reported, while noting the significance of recent Israeli discussions with Doha about continuing to fund Gaza. Hamas also thinks this is noteworthy, bragging over the weekend that it met with Qatar’s envoy Mohammed al-Emadi, and that $15 million was distributed in Gaza.In Israel, the Mossad-Qatar-Hamas story was revealed by Yisrael Beytenu leader Avigdor Liberman over the weekend, and was reported locally. The story goes that Mossad chief Yossi Cohen and IDF Southern Command Maj.-Gen. Herzi Halevi met with top Qatari officials.Halevi was in the news last month, when he commented on the killing of IRGC general Qasem Soleimani, saying that “we must look at the assassination as part of a fight between Iran and the US over Iraq’s character.” Halevi is known for his achievements in a three-year term running Military Intelligence. He has spoken about using deterrence in a way that does not escalate the situation, and of the importance of information supremacy over Israel’s enemies, according to an article at the Begin-Sadat Center for Strategic Studies in 2018. This is a key to Israel’s “campaign between the wars,” in which Israel must prepare for a future struggle with Iran and its allies.
Israel now has a dedicated headquarters for the “third circle” threat of Iran, in light of the IDF’s new Momentum Plan to enhance the IDF’s capabilities. It is worth grasping this larger picture to understand some of what Hamas is up to in Gaza. While Hamas and Palestinian Islamic Jihad both are supported by Iran, PIJ is an Iranian proxy whereas Hamas is more an ally. Hamas, however, has been isolated over the years, and has failed to achieve results in confrontation with Israel. Some 2,600 rockets fired over the last two years achieved little, and its “Great March of Return,” launched in 2018, also failed. In March 2018, former Palestinian prime minister Rami Hamdallah survived an assassination attempt in Gaza. Today Hamas is bragging about opposing the US “Deal of the Century.”It is important to consider that calculus to see the larger picture of Qatar’s role in Gaza. Qatar has supported Gaza for more than a decade, and the Emir of Qatar even visited Gaza in 2012. In January 2019, the third $15m. payment via Israel to Gaza was made by Qatar, as part of a 2018 deal. Mohammed al-Emadi has been Doha’s point man throughout. He has visited Israel more than two dozen times, according to a Reuters interview in 2018. He also cited talks between Israel and Hamas in that year. Qatar has said its aid to Gaza helps prevent a conflict. Emadi, however, has sometimes ruffled feathers in Gaza due to his outspokenness.
All of the ruffled feathers were forgotten when Hamas leader in Gaza, Yahya Sinwar, met Emadi at the end of last week to discuss a gas pipeline and financial aid. Twelve million was given to 120,000 families, $2m. for 500 Palestinians to get married, $1m. for tuition and another million for housing for the poor, according to a statement from Hamas.Hamas has done well internationally in the past few months. A delegation led by senior Hamas political leader Ismail Haniyeh went to Turkey, Malaysia, Qatar, and several other countries in December and January. Now Hamas says that its political bureau chief, Saleh al-Arouri, was in Egypt over the weekend of February 21 to discuss major issues. At the same time that Arouri was in Egypt, another Hamas delegation in Lebanon claimed to have met the head of Lebanese military intelligence for southern Lebanon. Hamas put out a press release naming their meetings with Lebanon’s Brig.-Gen. Fawzi Hamada, where they discussed the “Deal of the Century” and other issues.
It is also known that senior Hamas leader Ismail Haniyeh may remain outside Gaza for some time. He was in Iran for the funeral of Soleimani in January. Arouri, the deputy leader of Hamas, had only returned to Gaza in 2018 after eight years abroad. Now he is shuttling back and forth for the organization, having previously been based in Qatar, Lebanon and Turkey. He left Turkey in 2015.If we add all this up, what do we get? Hamas has struggled in Gaza since 2006, and has been isolated and broken down by numerous wars in 2009, 2012 and 2014. After tens of thousands of rockets built and fired, tunnels constructed and sea commandos trained, Hamas has little to show for it all, and wants a long-term deal.In Ramallah, the Palestinian Authority and its leaders in Fatah have been skeptical of what is going on in Qatar. Al Arabiya notes that the financial support, only $15m. in installments from Qatar every few months, seeks to divide the Palestinians further. Emadi is said to be working for a long-term deal or “calm,” and Hamas pays lip service to Palestinian unity, especially in the wake of the “Deal of the Century” announced in January, but it wants to use this “unity” to grow back its roots in the West Bank. Ramallah doesn’t want that.Saudi media says that other Qatari figures met with the Mossad head, including Mohammed bin Ahmed al-Misnad, who Al Arabiya calls the head of Qatari intelligence, and an adviser to the Emir. His official title is adviser for National Security. “The Mossad chief’s visit to Doha is the second in six months,” according to Al Arabiya’s sources. The report also notes that Qatar wanted to end funding for Gaza on March 30.
The overall picture is that Israel has elections coming up, Qatar is still in the middle of a dispute with other Gulf states, Iran wants to try to pressure Israel and there is opposition to Trump’s deal from Turkey and the PA. These reports come after Hamas’s globe-trotting in December and January, and prior to US Secretary of State Mike Pompeo’s trip to Saudi Arabia on February 20. In addition, the reports emerged after a spate of rumors in early February about Prime Minister Benjamin Netanyahu meeting Arab leaders in Cairo, which Saudi Arabia denied.
Overall, the meeting of key Israeli officials in Doha could be part of the growing relations between Israel and regional states. Turkey’s Anadolu news calls this the “Arab-Israeli normalization picking up pace in 2020.” It could just be a pragmatic way to keep funds flowing to Gaza, it could be linked to Iran’s pressure and Israel’s stated focus on Iran’s threats during the campaign between the wars and it is clearly linked to Hamas wanting more international attention. Israel has cautioned Hamas to stop attacks, after rocket fire and tensions in early February, warning of a “surprise.” It appears all around, regardless of the larger puzzle of Iran and the region, that it is in everyone’s interests to have some calm.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
IF YOU’RE READING THIS, YOU’RE PROBABLY TARGETED BY A GOVERNMENT OR TWO. SO I MADE SOMETHING FOR YOU. SEE DETAILS / ORDER
If the America and the world feel ran like Epstein’s Island, were the general population is the infantile victim class, well that’s because the feeling is accurate.
How Tony Blinken’s Stepfather Changed the World—and Him
Samuel Pisar was a Holocaust survivor who pushed rival nations to engage in commerce, and he left an imprint on the likely next secretary of State.
Samuel Pisar, photographed inside his home in Paris, France on May 2, 2010. Pisar is a renowned international lawyer, an author and a Knight of the French Legion of Honor. He was ten when his native Poland was invaded by Stalin and then Hitler. He survived the Nazi death camps of Majdanek, Auschwitz and Dachau, escaping at the age of 16. At the request of Leonard Bernstein, Pisar wrote the lyrics to Bernstein’s Symphony No. 3, the Kaddish. | Tomas van Houtryve / VII
One day in October 1986, an American lawyer who had the ear of presidents and corporate moguls was approached at a hotel by a group of Soviet Jews seeking help for members of their community.
The lawyer, a famed Holocaust survivor named Samuel Pisar, spoke Russian, among other languages. He was visiting Moscow with a delegation from the American Jewish Congress. Suddenly, however, he found himself asking a Soviet judge, and later a magistrate, to free five Soviet Jewish men who had been arrested on accusations of disturbing the peace during recent celebrations of the Jewish holiday of Simchat Torah. Pisar’s lawyerly efforts worked. The men were soon released to cheers from friends and family, although each was fined 50 rubles.
It was an unusual sight: An American advocating on behalf of Soviets in the Soviet legal system. But, in a sense, Pisar was the perfect man for the job. For years, he’d pushed for greater Western engagement with the Soviet Union and other adversarial nations, saying that through increased connections, chiefly trade, East and West could reduce the risk of a catastrophic military clash and improve the lives of people living under oppressive regimes. He encapsulated his ideas in a 1970 book titled Coexistence & Commerceas well as other writings, and his work informed U.S. presidents such as John F. Kennedy and Richard Nixon.
Pisar’s life story is remarkable on many levels. He was one of the youngest survivors of Adolf Hitler’s death camps, whisked to freedom by U.S. troops; he went from European black marketeer to receiving doctorates in law from Harvard and the Sorbonne; he advised French and American presidents and was granted U.S. citizenship through a special act of Congress; he served as a lawyer for Hollywood stars, corporate bigwigs, UNESCO and the International Olympic Committee; he was nominated for the Nobel Peace Prize; he wrote new text for Leonard Bernstein’s Symphony No. 3 (“Kaddish”) that shared his story through a conversation with God; and to his final days he worked to preserve the memory of the Holocaust.
Samuel Pisar at the Auschwitz Memorial in front of a map showing different locations from which people were deported to Auschwitz. | Sipa via AP Images
Pisar, who died in 2015, also left a lasting imprint on the man tapped to be America’s next secretary of State: his stepson, Antony Blinken. A suave, self-assured diplomat, Blinken has often spoken of how Pisar’s Holocaust survival story instilled in him the importance of maintaining America’s status as a beacon of freedom on a planet where too many remain in shackles.
Less discussed, though just as relevant now as Blinken prepares to tangle with adversaries like China, Iran, North Korea and Russia, are Pisar’s views on ways to improve relations between rival powers—views that have to some degree influenced his stepson. The main gist of Pisar’s idea—that ramping up connections, especially economic ones, will reduce tensions between adversaries—helped lay the intellectual groundwork for the Nixon policy of detente, and it has drawn plenty of acolytes as well as critics over the years. In the 1980s, elements of Pisar’s theory got a boost as Soviet leader Mikhail Gorbachev’s efforts to open up the Soviet system—exposing its citizens to ideas and goods from the West—helped lead to the fall of the communist bloc.
Today, his argument may seem like an obvious one, but as Pisar began laying it out in the 1950s, a decade dominated by the Korean War, confrontation with the Soviets and Sen. Joseph McCarthy’s hunt for communists inside the U.S. government, it was nothing short of groundbreaking.
While Pisar cast his theories primarily in the context of Western relations with the Soviet Union, he believed they also were relevant in other cases, including Western relations with China. But, perhaps more than any other example, China is now testing the hopes of people who, like Pisar, believe that commerce can help lead to peace. Despite years of increased trade, cultural and other ties between the United States, Europe and Beijing, tensions have spiked as the ruling Chinese Communist Party has become more authoritarian and oppressive. The U.S.-China relationship has further soured under President Donald Trump, who pursued a tariff-driven trade war with Beijing while alienating U.S. allies.
Now, Democrats all the way up to President-elect Joe Biden are signaling doubts about whether China will ever be anything but a foe to be confronted. Should Blinken be confirmed by the Senate, his handling of China could define his tenure at Foggy Bottom. It also could help further shape his stepfather’s geopolitical legacy, one that made Pisar especially proud because of his ardent desire to spare others the horrors he experienced as a child.
Secretary Blinken’s stepfather was a close confidant and lawyer for Ghislaine Maxwell’s father, Robert Maxwell. Pisar is reportedly one of the last people to have spoken to Maxwell before his death, according to the New York Times.
Among those arguing against any signs of despair are Mr. Maxwell’s son Ian and his lawyer and confidant, Samuel Pisar. They are among the last people, aside from the crew members, to talk to Mr. Maxwell. Both men spoke to him by phone aboard his yacht, around 11 P.M., about an hour after he returned from a solitary dinner in a restaurant in the port city of Santa Cruz.
Mr. Pisar said Mr. Maxwell seemed his normal, confident self and discussed plans and appointments. Ian Maxwell told reporters that his father had planned to travel to London the following day and that their conversation ended with Ian saying, “See you tomorrow, then,” and his father replying, “You bet.”
Obituary: Samuel Pisar, lawyer and holocaust survivor
Born: 18 March, 1929, in Bialystok, Poland. Died: 27 July, 2015 in Manhattan, New York City, aged 86
SAMUEL Pisar, who was ten when he entered the Holocaust and 16 when he was liberated by an American tank battalion, moved his Edinburgh Festival audience to tears at the Usher Hall a year ago when he narrated the Jewish mourning prayer, the Kaddish, to a symphony by his fellow Jew Leonard Bernstein. At Bernstein’s request, Pisar had written lyrics to the symphony as a Holocaust Oratorio, which reflected Pisar’s years as a boy in the Nazi extermination camps of Auschwitz, Dachau, Majdanek and Sachsenhausen. His father had been murdered by the Gestapo and his mother and little sister were gassed in the camps.
At the Usher Hall last August, when he was 85, he was accompanied by the Royal Scottish National Orchestra, conducted by the American John Axelrod, and by the Edinburgh Festival Chorus and the National Youth Choir of Scotland’s red-clad National Girls Choir led by Christopher Bell. The ensemble, and particularly Pisar, received a 15-minute standing ovation. Pilar said his recitals made him feel he was “saying Kaddish for all the six million”.
Bernstein had written the symphony and his own lyrics in memory of President John F Kennedy after his 1963 assassination.
But shortly before the great conductor died in 1990, he asked his dear friend Pisar to write new and stronger lyrics to reflect not only the tragedy of the Holocaust but the hope which drove the survivors.
Bernstein did not live to hear the new text, first performed to the backing of the Chicago Symphony Orchestra in 2003 and given added poignancy by America’s mourning of the 9/11 victims two years earlier.
Polish-born Pisar was a globally known lawyer based in New York and Paris, a foreign economic policy advisor to president John F Kennedy, the longtime lawyer and confidant of posthumously disgraced publisher Robert Maxwell, a lifelong supporter of human rights and a friend and advisor to French presidents François Mitterrand and Valéry Giscard d’Estaing.
He remained close to US presidents, including Barack Obama, for the rest of his life and represented movie stars including Elizabeth Taylor and corporate executives such as Steve Jobs. He also served as chief counsel to the International Olympic Committee and helped Sydney, Australia, a nation he had come to love, get the 2000 Olympic Games. He was an honorary ambassador for Unesco.
Pisar was one of the last people to speak to Maxwell, by phone, probably an hour before the chairman of Mirror Group Newspapers fell off his luxury yacht the Lady Ghislaine on 5 November, 1991.
“He had dined onshore in Santa Cruz (Tenerife), seemed his normal, confident self and discussed plans and appointments,” Pisar said. “He had planned to travel to London the following day and told his son Ian on the phone that he would see him tomorrow.”
Pisar attended the subsequent inquest in Madrid, which found that the publisher’s death was most likely caused by a heart attack and accidental drowning although conspiracy theorists maintain to this day he may have been murdered, something his family had at first contemplated but later rejected.
Pisar expressed shock when he learned, after the publishing magnate’s death, of his embezzlement of pension funds from his own Mirror Group.
Samuel Pisar was born on 18 March, 1929 in Bialystok, Poland, and was ten when the city was invaded by the Nazis in September 1939.
Young Sam, as he was always known, his little sister Frieda and his mother Helaina Suchowolski Pisar were taken immediately to concentration camps.
In his autobiography Of Blood and Hope, first published in 1979 and affirming the triumph of the human spirit, Pisar described how he got through the Holocaust through quick-wittedness, trickery and pitilessness – even to his fellow Jewish inmates.
When he was picked to die in the gas chambers, he grabbed an abandoned cleaning bucket and scrubbed the floor past the guards and back to his camp hut.
After the war, he maintained these “bad habits”, as he called them, to become a black marketeer and self-described “hooligan” in the American-occupied zone of Germany.
He sold American Lucky Strike cigarettes and coffee, stolen from the occupying troops, to German citizens, eventually earning enough to ride around on a BMW motorbike.
An aunt in Paris helped get him to Australia “to mend his reckless ways” and he later confessed: “If I had stayed in Europe, I might have become a terrorist or gangster.”
“Pisar was one of the last people to speak to Maxwell, by phone, probably an hour before the chairman of Mirror Group Newspapers fell off his luxury yacht the Lady Ghislaine on 5 November, 1991.”
He got a Bachelor of Laws degree from the University of Melbourne in 1953 before moving to the US for a Doctorate of Law from Harvard (where he first met former student JFK).
“There was a strange cohabitation within me of these two disparate human beings,” he once said. “The little feral child – sunken eyes, shaved head, skeletal – and suddenly the scholar who is pretending to compete as if he had a normal childhood and education.”
He later went to Paris for a further doctorate from the Sorbonne and his life thereafter became a pendulum between the US and France. In 1961, he was granted American citizenship through an Act of Congress and in 1974 was short-listed for the Nobel Peace Prize.
The man whose concentration camp number remained tattooed on his arm throughout his life was also named Grand Officer of the French Legion of Honour by then President Nicolas Sarkozy in 2012, an honorary officer of the Order of Australia (AO) by the Queen and a commander of Poland’s Order of Merit.
Samuel Pisar died of pneumonia after a stroke. He is survived by his second wife Judith, their daughter Leah, who worked in the White House for Bill Clinton, and daughters Helaina and Alexandra from his first marriage to Norma Pisar.
His stepson Tony Blinken is deputy US Secretary of State and former deputy national security adviser to President Obama.
Donald Blinken served as the chairman of the State University of New York system from 1978 to 1990 and was U.S. Ambassador to Hungary from 1994 to 1997, during the Clinton administration.
So our new Secretary of State Anthony Blinken’s stepfather, Samuel Pisar, was “longtime lawyer and confidant of…Robert Maxwell,” Ghislaine Maxwell’s Dad…
OK, so that’s just a coincidence. Moving on, Anthony Blinken “attended the prestigious Dalton School in New York City”…wait, what? https://t.co/DnE6AvHmJg
Dalton School…Dalton School…rings a bell
Donald Barr "hired Epstein to teach at Dalton when Epstein was merely a 20-year-old college dropout from both Cooper Union and New York University. Epstein only lasted at Dalton 2 years before he was hired by the investment bank Bear Stearns"
— Rudy Havenstein, Senior Markets Commentator. (@RudyHavenstein) September 17, 2020
I’m not going to even mention that Blinken’s stepdad Sam Pisar’s name was in Epstein’s “black book.”
Lots of names in that book. I mean, for example, Cuomo, Trump, Clinton, Prince Andrew, Bill Cosby, Woody Allen – all in that book, and their reputations are spotless.
Samuel Pisar was the Maxwell family’s “long-trusted attorney.”
Based in Paris, Pisar “had become one of [Robert] Maxwell’s few confidants and probably his closest business adviser. He had helped pave Maxwell’s entry into Israel’s business community.”
“Could it be that no one wanted a thorough investigation?”
I do find the claim that Maxwell’s “long-trusted” attorney Pisar, “one of [Robert] Maxwell’s few confidants and probably his closest business adviser,” didn’t know Robert was working for Mossad a bit of a stretch.
Our Secretary of State Antony Blinken went to the Dalton School, and his stepdad Samuel Pisar was tight with both Robert Maxwell, Ghislaine’s dad and spy, & apparently Jeff Epstein (that French article above).
The “Rappaport” mentioned here would be Bruce Rappaport (#GIK).
Pisar is Blinken’s stepdad, of course, not Blinken, but still…so many odd coincidences.
**BREAKING** More dirty money from Ukraine wrapped up in the Biden administration…
Secretary of State Blinken and his cabinet secretary wife allegedly attempted to influence US officials on behalf of Burisma.
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
IF YOU’RE READING THIS, YOU’RE PROBABLY TARGETED BY A GOVERNMENT OR TWO. SO I MADE SOMETHING FOR YOU. SEE DETAILS / ORDER
If it walks like graphene and quacks like graphene, you don’t even need to name the graphene
Neural electrodes are used for acquiring neuron signals in brain-machine interfaces, and they are crucial for next-generation neuron engineering and related medical applications. Thus, developing flexible, stable and high-resolution neural electrodes will play an important role in stimulation, acquisition, recording and analysis of signals. Compared with traditional metallic electrodes, electrodes based on graphene and other two-dimensional materials have attracted wide attention in electrophysiological recording and stimulation due to their excellent physical properties such as unique flexibility, low resistance, and high optical transparency. In this review, we have reviewed the recent progress of electrodes based on graphene, graphene/polymer compounds and graphene-related materials for neuron signal recording, stimulation, and related optical signal coupling technology, which provides an outlook on the role of electrodes in the nanotechnology-neuron interface as well as medical diagnosis.
Elon Musk, the maverick tech entrepreneur who, after creating luxury electric cars with Tesla Motors and reusable rockets with SpaceX, plans to colonize Mars and then bootstrap an interplanetary civilization, is working to develop operational, high-speed Brain-Computer Interfaces (BCI) based on a family of futuristic technologies that he calls “neural lace.” Future neural lace tech could permit sending information back and forth between the brain and a computer – or the cloud – at ultra-high bandwidth.
“Your phone and your computer are extensions of you, but the interface is through finger movements or speech, which are very slow,” said Musk, as reported by Vanity Fair. “For a meaningful partial-brain interface, I think we’re roughly four or five years away.”
That might be a little over-optimistic. But last week scientists funded by the European Commission reported BCI advances based on graphene transistor arrays for high resolution brain imaging, which can be seen as precursors and enablers of full-blown neural lace tech. Other scientists are beginning to cross the bridge between life and computers in the other direction as well, with genetically engineered programmable cells that could one day act as tiny computers and robots within the body.
….
We might have to wait a little while for promising research advances in neural lace and programmable cells to become medical reality for therapy and enhancement. But other forms of enhancement could become practical reality sooner and, for example, allow older women to become pregnant by having their ovaries rejuvenated.
The future is marching toward us, perhaps even running. If you find that stressful, you could talk to your doctor about medical marijuana, whose anti-stress properties have been confirmed by a recent study.
New experimental treatment seems to rejuvenate ovaries and allow older women to get pregnant. Researchers at the Genesis Athens Clinic in Greece have found ways to allow menopausal women, thought to be infertile, to become pregnant using their own eggs, New Scientist reports. The scientists have used a technique that seems to rejuvenate ovaries, but how that happens isn’t clear at the moment. The researchers are now planning clinical trials in Greece and the US. If these research findings are confirmed and shown to work in practice, a treatment could be developed to enable older women to get pregnant.
…
Elon Musk’s new company Neuralink wants to develop visionary brain implants. Elon Musk, the superstar futurist and entrepreneur who founded and runs Tesla Motors and SpaceX, wants to merge human brains and computers next, WSJ reports. Tesla Motors Club has a non-paywalled copy of the WSJ article. Musk co-founded Neuralink Corp. to pursue “neural lace” technology – brain implants that may one day upload and download thoughts. A first iteration of neural lace technology could consist of thin and flexible tissue-like electronic chips rolled up in a needle, injected in the brain, and then unrolling and blending with the brain’s neural circuitry. The WSJ spoke with Neuralink co-founder Max Hodak and Boston University Prof. Timothy Gardner, who joined the company. Bryan Johnson, the wealthy founder of online payments company Braintree, launched a well-funded startup called Kernel to pursue similar developments.
Flexible graphene probes record brain activity in high resolution. Researchers associated with the Graphene Flagship project of the European Commission have developed flexible devices, based on graphene field-effect transistors, for recording brain activity in high resolution. The research work, published in 2D Materials, shows that arrays of 16 graphene-based transistors, each with an active area less than the cross section of a human hair, arranged on a flexible substrate and placed on the surface of the brain, permit recording of neural activity by detecting electric fields generated when neurons fire. The researchers suggest that this technology could lay the foundation for a future generation of in-vivo implants for therapeutic brain stimulation technologies and interfaces for sensory and motor devices. Of course, hidden between the lines of the aseptic bureaucratese favored by the European Commission, there’s the prospect of visionary technologies like Musk’s neural lace.
Synthetic biologists advance toward programmable mammalian cells. Scientists led by Wilson Wong, a synthetic biologist at Boston University, have found ways to genetically engineer the DNA of mammalian cells to carry out complex computations, in effect turning the cells into biocomputers. By cutting, pasting and reassembling DNA strands, the researchers built 113 different circuits, each designed to carry out a different logical operation, with a 96.5 percent success rate, The study, published in Nature Biotechnology, has been covered by Wired. The researchers hope programmable cells will have a big impact on medicine, for example by improving the immune system with artificial genetic circuits that detect and wipe out tumors, or synthetically generating biological tissues on demand.
Paper: Mapping brain activity with flexible graphene micro-transistors
Benno M Blaschke1, Núria Tort-Colet2, Anton Guimerà-Brunet3,4, Julia Weinert2, Lionel Rousseau5, Axel Heimann6, Simon Drieschner1, Oliver Kempski6, Rosa Villa3,4, Maria V Sanchez-Vives2,7
Establishing a reliable communication interface between the brain and electronic devices is of paramount importance for exploiting the full potential of neural prostheses. Current microelectrode technologies for recording electrical activity, however, evidence important shortcomings, e.g. challenging high density integration. Solution-gated field-effect transistors (SGFETs), on the other hand, could overcome these shortcomings if a suitable transistor material were available. Graphene is particularly attractive due to its biocompatibility, chemical stability, flexibility, low intrinsic electronic noise and high charge carrier mobilities. Here, we report on the use of an array of flexible graphene SGFETs for recording spontaneous slow waves, as well as visually evoked and also pre-epileptic activity in vivo in rats. The flexible array of graphene SGFETs allows mapping brain electrical activity with excellent signal-to-noise ratio (SNR), suggesting that this technology could lay the foundation for a future generation of in vivo recording implants.
In March 2014, CureVac won a €2 million prize awarded by the European Commission to stimulate new vaccine technologies.[17] Later, in July 2014, CureVac signed an exclusive license agreement with Sanofi Pasteur to develop and commercialize an mRNA-based prophylactic vaccine.[18] By September 2014, the company licensed the global rights for its Phase I candidate – CV9202 – to Boehringer Ingelheim. Boehringer was to conduct trials using the mRNA vaccine in combination with afatinib in advanced and/or metastatic epidermal growth factor receptor (EGFR) mutated non-small cell lung cancer (NSCLC) as well as inoperable stage III NSCLC.[19]
In March 2015, a CureVac investor, the Bill & Melinda Gates Foundation, agreed to provide separate funding for several projects to develop prophylactic vaccines based on CureVac’s proprietary mRNA platform.[20] By September 2015, CureVac entered into a collaboration with the International AIDS Vaccine Initiative (IAVI) to accelerate the development of AIDS vaccines, utilizing immunogens developed by IAVI and partners, delivered via CureVac’s mRNA technology.[21] That same month, CureVac announced it would open a United States hub in Boston, Massachusetts.[22]
In accordance with its deal with Lilly, the company began construction on a production facility in 2016.[23]
In February 2019, the Coalition for Epidemic Preparedness Innovations (CEPI) awarded CureVac a $34 million grant from to develop its proprietary “RNA printer” prototype.[24] The technology is expected to allow the company to rapidly produce mRNA vaccine candidates at scale, from multiple locations globally, to bypass the logistical hurdles that often delay the production of vaccines in response to infectious disease emergencies, and also enable the production of personalized medicines.[24] The initial uses would be for their candidate vaccines for Lassa fever, yellow fever, and rabies.[24]
In July 2020, Tesla, Inc CEO Elon Musk announced via Tweet that Tesla and CureVac had reached an agreement to produce portable “RNA microfactories” based on this technology to manufacture CureVac’s COVID-19 vaccine candidate.[24] CureVac had stated that the bioprinters would be able to produce “more than a hundred thousand doses” within approximately two weeks.[24] At approximately the same time, Tesla and CureVac filed a joint patent on the technology.[25] In August, Musk reviewed the project with Curevac while in Germany.[25]
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them
Dream hacking and dream engineering are here. Sweet dreams, biped cattle! Unless you’re dreaming of beer because Coors Light paid some psycho-nerds a truckload of money.
Coors Light’s Big Game Commercial Dream Experiment (2021)
Credits for this report go almost entirely to Truthstream Media, who have been in my Top5 Favorite Video Content Creators for longer than I can remember now, and their latest piece is no disappointment. I just followed the breadcrumbs they left and went a bit further.
Xbox Looks Deep Into Gamers’ Lucid Dreams Right After They Play
215 McCann work explores ‘Targeted Dream Incubation’
We love it when advertising goes a step further than it needs to, bringing us to a place where we can imagine possibilities we hadn’t considered this morning.
Xbox’s “Made From Dreams,” part of the “Power Your Dreams” campaign, is one such effort. Created to promote the Xbox Series X, it’s the fruit of a partnership with 215 McCann and dream scientists engaged in so-called Targeted Dream Incubation methods—a technique for guiding dreams toward specific themes. A lot of the research can be found in a special edition of the Consciousness and Cognition journal, which focused on dream engineering in its fall issue.
The work basically involves Xbox triggering lucid dreams, then invading them, Inception-style. Lucid dreaming is when you become aware you’re dreaming, and can control the dream. There are a lot of interesting benefits to being able to lucid dream—like safely exploring, and even finding catharsis for, traumas, fears, fantasies and different life possibilities.
And it’s a muscle you can develop! Here’s a primer on how it works and what techniques can be used to strengthen this ability.
In “Made From Dreams,” 215 McCann and Xbox worked with gamers who used the Series X console for the first time before sliding into sleep. Once the gamers were in a semi-lucid state known as hypnagogia—a liminal space between asleep and awake—researchers used a dream recording technology called Hypnodyne to explore dreams as they hatched them.
The series kicks off with “Lucid Odyssey,” featuring streamer MoonLiteWolf and directed by Taika Waititi.
Actual audio recorded from the dream study features in the work, which is otherwise visually embellished by Waititi’s fine hand. For anyone with an ounce of exposure to dream logic, what MoonLiteWolf encounters and sees is appropriately alien yet relatable. We’re especially fond of the weird profundities that dreamfolk always tend to spout.
“Was I supposed to fly this whole time?” she wonders.
“You’re supposed to go wherever you go,” a glowing bunny tells her.
And of course, because she just played Halo a minute ago, Master Chief appears as a deejay with a cat head, spinning an EDM version of the Halo Monk Chant. Nice, Xbox!
Football player Odell Beckham Jr. gets the treatment next. He also gets a custom controller and some Air Force 1’s, customized to match his dreamscape and experiences. Lucky.
Last comes Steve Saylor, or BlindGamerSteve, who walks us through his dreams after playing Destiny 2: Beyond Light. In this case, 3-D spatial sound brings his basic descriptive recording to life: “Close your eyes,” Xbox tells us in its YouTube description, “and let the soundscapes of Steve’s dreams take you to Europa—and beyond.”
Each video approaches the same study in a different creative way, which is a cool touch; otherwise, listening to people’s dreams—in a scientific setting, to boot—can be a drag. Work like this also inspires a desire to explore our own liminal possibilities. It also helps if you can get a custom controller and some shoes out of the deal.
The video below loosely describes the science and procedures used, and summarizes the campaign nicely.
All this is designed to remind you that “the next generation of Xbox consoles is what dreams are made of—literally.” We’ll ignore that trite little PR pretext and focus instead on the overall coolness of this work: It provided creative collaborators with a unique experience, and was clearly fun for the agency and team to work on. Some effort was made to make this interesting for viewers. Lastly, exposing more people to lucid dreaming, especially in a time when so much already feels like a chaotic waking dream, is more of a social plus than a minus.
If you’re looking for a more coherent justification for its existence, we like OBJ’s observation: “Gaming to me is like being in a dream world. It takes you to a whole ‘nother place.” Having lost whole days and nights to No Man’s Sky, we know this to be true.
A few other creative efforts support these core videos. Artist Quentin Deronzier created a series of digital artworks inspired by Stallion83‘s dreams, themselves heavily influenced by Assassin’s Creed Valhalla. And digital creator Johanna Joskowska created AR social filters that enabled fans to load different game-themed experiences from Emericagirl24‘s dreams, which playfully explore aspects of Cyberpunk 2077.
Molson Coors recently announced a new kind of advertising campaign. Timed for the days before Super Bowl Sunday, it was designed to infiltrate our dreams [1]. They planned to use “targeted dream incubation” (TDI) [2] to alter the dreams of the nearly 100 million Super Bowl viewers the night before the game—specifically, to have them dream about Coors beer in a clean, refreshing, mountain environment—and presumably then drink their beer while watching the Super Bowl. Participants in what Coors called ‘the world’s largest dream study’ would get half off on a 12 pack of Coors; if they sent the link to a friend who also incubated their dreams, the 12 pack was free. With this campaign, Coors is proudly pioneering a new form of intrusive marketing. “Targeted Dream Incubation (TDI) is a never-before-seen form of advertising,” says Marcelo Pascoa, Vice President of Marketing at Molson Coors [3].
With brain imaging techniques beginning to capture the core contents of people’s dreams [4] and sleep studies establishing real-time communication between researchers and sleeping dreamers [5], the kind of dream incubation until recently assumed to be the pure science fiction of movies like Inception is now becoming reality. Coors is not the only company expressing interest in using these novel dream incubation technologies: Xbox’s Made From Dreams uses TDI to give professional gamers dreams of their favorite video games, while Playstation advertises a new Tetris game based on a sleep study demonstrating that gameplay incubates Tetris dreams [5]. In 2018, Burger King created a “nightmare” burger for Halloween, claiming that a sleep laboratory study had ‘clinically proven’ it would induce nightmares [6]. And multiple marketing studies are openly testing new ways to alter and motivate purchasing behavior through dream and sleep hacking [7, 8]. The commercial, for-profit use of dream incubation is rapidly becoming a reality.
Traditions of dream incubation—techniques employed during wakefulness to help a person dream about a specific topic—go back thousands of years and span indigenous practices across the globe. Over the last few years, brain scientists have begun to develop scientific tools that facilitate this incubation of specific dream content [2], making dream incubation more targeted and measurable, and allowing scientific experimentation on the nature and function of dreaming. They use sensors to determine when an individual’s sleeping brain is receptive to external stimuli and, at these times, introduce smells, sounds, flashing lights or even speech to influence the content of our dreams [9].
This video was made by McMaster Demystifying Medicine students Navroop Gosal, Jiayi Mo, Xiuyuan Song and Sara Warsi – McMaster University 2020
Dreams have ties to people’s well-being [10, 11], and dream content can predict how well someone will adapt to waking challenges and concerns, including those related to trauma and depression [12, 13]. Altering dream content can augment our creativity, boost our mood, and help us learn [14, 15]. We believe that targeted intervention in sleep and dreams could help alleviate several psychiatric conditions including depression and PTSD [12]. We know that targeted delivery of odors during sleep can help combat addiction; participants exposed during their sleep to the smells of cigarettes along with those of rotten eggs smoked 30% fewer cigarettes over the following week [16]. Researchers have not yet tested whether TDI can instead worsen addiction, but the Coors study, which paired images of beer cans not with odious smells but with images of clean mountain streams, may shine a disturbing light on this question. Regardless, such interventions clearly influence the choices our sleeping and dreaming brain make in how to interpret the events from our day, and how to use memories of these events in planning our future, biasing the brain’s decisions toward whatever information was presented during sleep [17, 18].
These questions and developments should be considered in the broader context of sleep and memory research. The last twenty years have been a watershed for sleep research during which we have come to understand the importance of sleep for our memories and emotional health. It is while we sleep that our brain decides which memories to keep and which to forget, and how to organize those it keeps [19, 20]. It also can choose to keep the gist or the emotional core of a memory while letting other details be forgotten [20, 21]. Through this nocturnal process, the brain shapes the memories that together create our autobiographical past, our sense of who we are now, and our understanding of how best to live our lives in the future.
More recent studies have shown that dreaming represents another aspect of this nightly memory evolution. Our dreams are not attempts to suppress undesirable wishes, nor are they simply the result of random brain activity during sleep. Dreaming represents an evolved mechanism for exploring the relevance and importance of older memories to newer ones, seeking to position the events of our day among the innumerable memories and concepts we have accumulated across a lifetime [18], helping to make us just a bit wiser in the process.
For now, TDI-based advertising requires our active participation, for example choosing to play an 8-hour Coors soundtrack while we sleep. But it is easy to envision a world in which smart speakers—40 million Americans currently have them in their bedrooms [22]— become instruments of passive, unconscious overnight advertising, with or without our permission. These tailored soundtracks would become background scenery for our sleep, as the unending billboards that litter American highways have become for our waking life.
Our dreams cannot become just another playground for corporate advertisers. Regardless of Coors’ intent, their actions set the stage for a corporate assault of our very sense of who we are. And it is not difficult to imagine Coors’ ad campaign negatively impacting abstinent alcoholics. Indeed, research has shown that abstinent drug users who report dreaming about their drug-use show higher levels of craving [23]. In the cigarette cessation study mentioned above, not only was the intervention effective in sleep (yet ineffective when the smells were presented during wake), but participants reported no memory of being exposed to these smells in the morning. The potential for misuse of these technologies is as ominous as it is obvious.
TDI-advertising is not some fun gimmick, but a slippery slope with real consequences. Planting dreams in people’s minds for the purpose of selling products, not to mention addictive substances, raises important ethical questions. The moral line dividing companies selling relaxing rain soundtracks to help people sleep from those embedding targeted dreams to influence consumer behavior is admittedly unclear at the moment. While the Federal Trade Commission has indicated that subliminal ads during wake violate its statute requiring truth in advertising, there is no similar indication regarding exposure to advertisements during sleep.
As sleep and dream researchers, we are deeply concerned about marketing plans aimed at generating profits at the cost of interfering with our natural nocturnal memory processing. Brain science helped design several addictive technologies, from cell phones to social media, that now shape much of our waking lives; we do not want to see the same happen to our sleep. We believe that proactive action and new protective policies are urgently needed to keep advertisers from manipulating one of the last refuges of our already beleaguered conscious and unconscious minds: Our dreams.
Robert Stickgold – Harvard Medical School, Boston MA, coauthor of When Brains Dream
Antonio Zadra – Université de Montréal, Canada, coauthor of When Brains Dream
Adam Haar – M.I.T., Cambridge MA, co-developer of TDI tools
Signatories
Judith Amores – Harvard Medical School, Boston MA
Thomas Andrillon – Monash University, Australia
Kristoffer Appel – Institute of Sleep and Dream Technologies, Germany
Ryan Bottary – Boston College, Boston MA
Kelly Bulkeley – The Sleep and Dream Database, Portland OR
Tony Cunningham – Harvard Medical School, Boston MA
Per Davidson – Lund University, Sweden
Teresa DeCicco – Trent Univ, Canada
Eden Evins – Harvard Medical School, Boston MA
Rockelle Guthrie – David Geffen School of Medicine, University of California, Los Angeles
David Kahn – Harvard Medical School, Boston MA
Alexandra Kitson – Simon Fraser University, Canada
Karen Konkoly – Northwestern University, Evanston IL
Célia Lacaux – Paris Brain Institute (ICM) – Paris, France
Anthony Levasseur – Université de Montréal, Canada
Pattie Maes – M.I.T., Cambridge MA
Louis-Philippe Marquis – Université de Montréal, Canada
Patrick McNamara – Boston University, Boston MA
Sara Mednick – University of California, Irvine
Natália Bezerra Mota – Federal University of Pernambuco and Federal University of Rio de Janeiro
Delphine Oudiette – Paris Brain Institute (ICM) – Paris, France
Edward Pace-Schott – Harvard Medical School, Boston MA
Ken Paller – Northwestern University, Evanston IL
Jessica Payne – University of Notre Dame, South Bend IN
Claudia Picard-Deland – Université de Montréal, Canada
Leila Salvesen – IMT School for Advanced Studies Lucca / Donders Institute
Sophie Schwartz – University of Geneva, Switzerland
Paul Seli – Duke Univ., Durham NC
Carlyle Smith – Trent University, Canada
Matthew Spellberg — Harvard University, Cambridge, MA
Katja Valli – University of Turku, Finland
Tomás Vega – M.I.T, Cambridge MA
Erin Wamsley – Furman University, SC
Marco Zanasi – Torvergata Univ, Italy
Morteza Zangeneh Soroush – Tehran University of Medical Sciences
4. Horikawa, T., Tamaki, M., Miyawaki, Y., & Kamitani, Y. (2013). Neural decoding of visual imagery during sleep. Science, 340(6132), 639-642. doi:10.1126/science.1234330
5. Konkoly, K., Appel, K., Chabani, E., Mironov, A. Y., Mangiaruga, A., Gott, J., . . . Witkowski, S. (2021). Real-time dialogue between experimenters and dreamers during REM sleep. Current Biology, in press. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3606772
9. Solomonova, E., & Carr, C. (2019). Incorporation of external stimuli into dream content. In K. Valli & R. Hoss (Eds.), Dreams: Biology, Psychology and Culture (pp. 213-218). Westport, CT: Greenwood Publishing Group.
10. Pesant, N., & Zadra, A. (2006). Dream content and psychological well-being: a longitudinal study of the continuity hypothesis. J Clin Psychol, 62(1), 111-121. doi:10.1002/jclp.20212
11. Sandman, N., Valli, K., Kronholm, E., Vartiainen, E., Laatikainen, T., & Paunio, T. (2017). Nightmares as predictors of suicide: an extension study including war veterans. Sci Rep, 7, 44756. doi:10.1038/srep44756
12. Cartwright, R. (1991). Dreams that work: The relation of dream incorporation to adaptation to stressful events. Dreaming, 1, 3-9.
13. Mellman, T. A., David, D., Bustamante, V., Torres, J., & Fins, A. I. (2001). Dreams in the Acute Aftermath of Trauma and Their Relationship to PTSD. Journal of Traumatic Stress, 14, 241-247. doi: https://doi.org/10.1023/A:1007812321136
14. Barrett, D. (2001). The committee of sleep : How artists, scientists, and athletes use dreams for creative problem-solving–and how you can, too. New York: Crown Publishers.
15. Erlacher, D., & Schredl, M. (2010). Practicing a motor task in a lucid dream enhances subsequent performance: A pilot study. The Sport Psychologist, 24(2), 157-167.
16. Arzi, A., Holtzman, Y., Samnon, P., Eshel, N., Harel, E., & Sobel, N. (2014). Olfactory aversive conditioning during sleep reduces cigarette-smoking behavior. J Neurosci, 34(46), 15382-15393. doi:10.1523/JNEUROSCI.2291-14.2014
17. Hu, X., Antony, J. W., Creery, J. D., Vargas, I. M., Bodenhausen, G. V., & Paller, K. A. (2015). Cognitive neuroscience. Unlearning implicit social biases during sleep. Science, 348(6238), 1013-1015. doi:10.1126/science.aaa3841
18. Zadra, A., & Stickgold, R. (2021). When Brains Dream. New York: W.W. Norton.
20. Payne, J. D., Stickgold, R., Swanberg, K., & Kensinger, E. A. (2008). Sleep preferentially enhances memory for emotional components of scenes. Psychological Science, 19(8), 781-788. doi:10.1111/j.1467-9280.2008.02157.x
23. Tanguay, H., Zadra, A., Good, D., & Leri, F. (2015). Relationship between drug dreams, affect, and craving during treatment for substance dependence. J Addict Med, 9(2), 123-129. doi:10.1097/ADM.0000000000000105
According to a MIT Media Lab study on dream engineering, “nearly any sensory stimuli has potential for modulating experience in sleep.”
And we’ve learned that where MIT is involved, the military and DARPA are very likely to be be involved. So, unsurprisingly, this just came out in Popular Mechanics magazine:
A Department of Defense-led research project wants to modulate REM sleep to help ease stress.
The study also aims to enhance REM sleep in order to consolidate traumatic memories.
Controlling REM sleep could offer multiple health benefits, but also opens the door to additional theories.
The Department of Defense wants to see if anyone out there can control rapid eye movement (REM) sleep. The department has put out a call for submissions to do just that, all with the goal of easing stress and traumatic memories. But there could be more to the equation.
The Defense Advanced Research Projects Agency (DARPA) and Defense Sciences Office issued what it calls a Disruption Opportunity, “inviting submissions of innovative basic or applied research concepts in the technical domain of neuromodulation as a means of enhancing rapid eye movement (REM) sleep mechanisms associated with stress adaption and traumatic memory consolidation.”
The feasibility study and proof of concept would be worth $1 million for the team with the winning submission.
The goal is to learn how to modulate—or control—REM sleep to help ease stress and post-traumatic stress. But there’s speculation that we can expect a bit more from this Opportunity than understanding REM sleep. In a Sociablepost, the outlet posits that “the idea of modulating and even artificially implanting dreams is not far off.”
As Sociablenotes, the Department of Defense Disruption Opportunity doesn’t mention anything about dream incubation. But the continued investigation of everything from targeted dream incubation to targeted memory reactivation isn’t necessarily that far off from the “memory consolidation” the DARPA brief calls for.
However, at the moment, this is all speculation. And while it may be exciting to think about a real-life incarnation of the movie Inception, the stated goal of the DARPA effort—using REM sleep to help understand how to control sleep in order to reduce sleep disturbances and prevent PTSD—is nothing to sneeze at in and of itself.
A 2015 study in the Biology of Mood & Anxiety Disorders highlights how post-traumatic stress disorders often come accompanied by disturbed sleep, including fragmented rapid eye movement. The study notes that sleep disturbance resulting from acute trauma may contribute to PTSD, and that continued sleep disturbances can exacerbate PTSD.
“We suggest that optimizing sleep quality following trauma, and even strategically timing sleep to strengthen extinction memories therapeutically instantiated during exposure therapy,” the authors write, “may allow sleep itself to be recruited in the treatment of PTSD and other trauma and stress-related disorders.”
Using targeted sleep improvements to better the health of patients, including veterans suffering from post-traumatic stress disorder, could offer up a new tool to helping improve the post-military life of United States military personnel.
Now, DARPA is looking to develop a novel cognitive science tool that enlists machine learning and “physiological sensors” to detect what someone believes to be true.
If this technology ever makes it way into the general population through the Internet of Bodies (IoB) ecosystem of inter-connected devices that can be worn, swallowed, or implanted — then Harari’s dystopian scenario could prove truly prophetic.
The proverbial “they” would know your reaction to what the authorities were saying, know if you believed them or not, and could take action against you.
“If we allow the emergence of such total surveillance regimes, don’t think that the rich and powerful in places like Davos will be safe” — Yuval Harari, WEF, 2020
“By bringing together recent advances in cognitive science, neuroscience, physiological sensors, data science and machine learning,” DARPA says, “the NEAT program will develop processes that can measure what a person believes to be true.”
This will be possible by:
Presenting carefully crafted stimuli that are designed to evoke specific preconscious mental processes.
Detecting the resulting preconscious processes using current physiological sensors combined with state-of-the-art signal processing and neural analytics.
Using advances in machine learning and data science to aggregate the preconscious responses collected across a set of stimuli into a final measurement that quantifies what a person believes to be true for a specific topic.
“We are no longer mysterious souls; we are now hackable animals” — Yuval Harari, WEF, 2020
According to Harari, “To hack human beings you need a lot of biological knowledge, a lot of computing power, and especially a lot of data.
“If you have enough data about me and enough computing power and biological knowledge, you can hack my body, my brain, my life. You can reach a point where you know me better than I know myself.”
The historian even came up with a “danger formula” for hacking human beings, which he believes “might be the defining equation of life in the 21st Century.”
That equation is B x C x D = AHH — which means Biological knowledge multiplied by Computing power multiplied by Data equals the Ability to Hack Humans.
“The power to hack human beings can of course be used for good purposes like provided much better healthcare,” said Harari, adding, “but if this power falls into the hands of a 21st Century Stalin, the result will be the worst totalitarian regime in human history, and we already have a number of applicants for the job of 21st Century Stalin.”
In his “How to Survive the 21st Century” speech at Davos in 2020, Harari warned:
“After four billion years of organic life shaped by natural selection we are about to enter a new era of inorganic life shaped by intelligent design — our intelligent design is going to be the new driving force of the evolution of life.”
“Governments, corporations, and armies are likely to use technology to enhance human skills that they need like intelligence and discipline while neglecting other human skills like compassion, artistic sensitivity, and spirituality,” he added.
“The result,” according to Harari, “might be a race of humans who are very intelligent and very disciplined, but lack compassion, lack artistic sensitivity, and lack spiritual depth.”
What Harari doesn’t realize is that the race he’s talking about is here, he and his psychopathic buddies in Davos and wherever, doing this type of works, are that race of soulless Borgs, even though still organic for the most part.
The goal is to turn humans into non-thinking automatons [Human 2.0], which can be tracked traced via IOB, scored by behavioural, social and environmental analytics, to be bought and sold as human capital investments. pic.twitter.com/zKzWGzmF9n
To be continued? Our work and existence, as media and people, is funded solely by our most generous supporters. But we’re not really covering our costs so far, and we’re in dire needs to upgrade our equipment, especially for video production. Help SILVIEW.media survive and grow, please donate here, anything helps. Thank you!
! Articles can always be subject of later editing as a way of perfecting them


























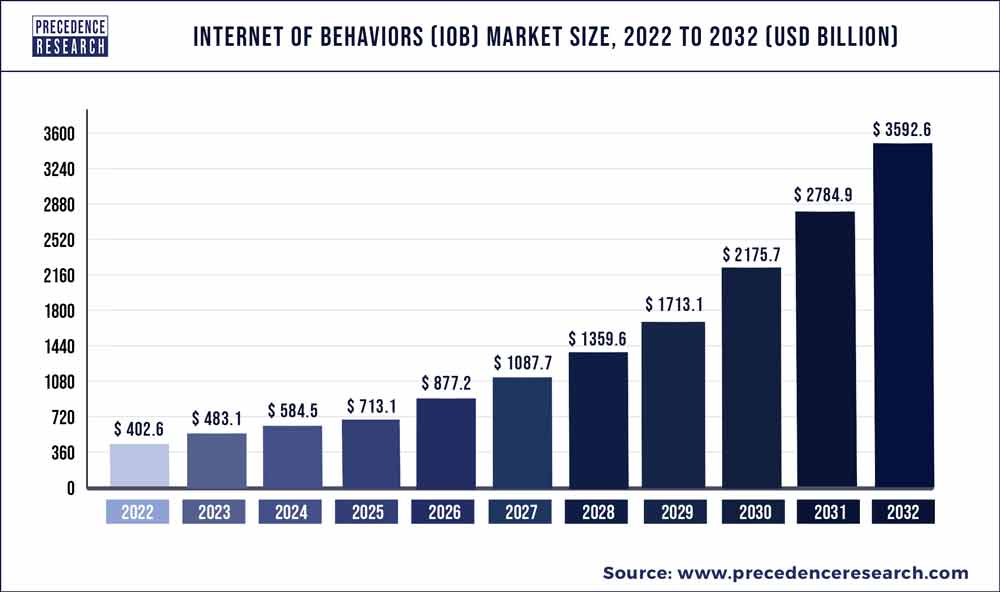




 and the Emir of Qatar Sheikh Hamad bin Khalifa al-Thani arrive at a cornerstone laying ceremony in the southern Gaza Strip")
























